
Language resources play a key role in research in humanities and in the development of NLP applications. Working Group 1 aims to bring the benefits of the linked data paradigm to them in order to make them more easily discoverable, reusable and interoperable both with one another and with the tools consuming them. To this aim, the group addresses their creation, interlinking, enrichment, quality assessment and evolution from a linked data perspective. This concerns different tasks on which the work of our community hinges: i) the modelling of linguistic information as linked data, ii) the creation and evolution of the linguistic resource itself, iii) its interlinking with other resources and iv) its quality assessment.
Throughout the life cycle of the language resource, it is crucial to take into account the features of the language(s) it concerns to identify which aspects are language-dependent, and thus provide equal support to both resourced and under-resourced languages. As one of the goals of our Action is to help bridge the wide gap in technological support and available data between resourced and under-resourced languages, in WG1 we have a taskforce concerned specifically with the analysis and development of language technologies for under-resourced languages and domains from a linked data perspective. As such, we are elaborating a policy brief for promoting a better inclusion of the latter.
As starting point, in order to create a linked-data based language resource we first need to analyse which features are present in the original data (or which features are expected, if the resources is created in linked data from scratch), assess the representation needs, and select, adapt or create a linked data vocabulary to reuse in order to represent the encoded information as linked data. This step is focused thus on the modelling of linguistic information as linked data. In particular, it is concerned with updating, extending and improving already existing vocabularies for creating linguistic linked data resources. For instance, our members working on modelling are heavily involved in the development of new modules for the de-facto standard for lexical data representation on the Web, OntoLex-Lemon, under the auspices of the W3C OntoLex-Lemon group. These include specialized modules to cover morphological and corpus information in linked data lexicons. Together with Working Groups 3 and 4 in the Action, we are also collaborating with the OntoLex-Lemon community to analyse and address the modelling needs arising from multimodal data. Since the modelling of linguistic information as linked data is a cornerstone in the development of resources for the use cases of the technologies developed in the Action, there is a close collaboration between WG1 and WG4. An example of this is an ongoing work pertaining to diachronic lexical data carried out between the two groups.
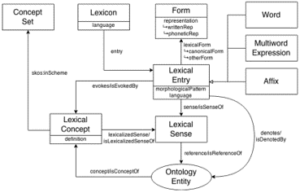 However, creating a linked data-based language resource does not only concern modelling. To contribute to the development of language resources in a collaborative setting, we also analyse the current landscape of linked data resources published on the LLOD cloud, taking into account their availability, their quality, and the languages and domains they cover. This allows us to gather insights into the tendencies in language resource publication, the use of metadata, and gaps in language and domain coverage needing solution. In addition, with the goal of promoting and supporting the adoption of LD principles in the creation of language resources, we also investigate the main obstacles preventing their (re)use, together with the need for (semi)automatic tools/services to enhance the exploitation of linked data.
However, creating a linked data-based language resource does not only concern modelling. To contribute to the development of language resources in a collaborative setting, we also analyse the current landscape of linked data resources published on the LLOD cloud, taking into account their availability, their quality, and the languages and domains they cover. This allows us to gather insights into the tendencies in language resource publication, the use of metadata, and gaps in language and domain coverage needing solution. In addition, with the goal of promoting and supporting the adoption of LD principles in the creation of language resources, we also investigate the main obstacles preventing their (re)use, together with the need for (semi)automatic tools/services to enhance the exploitation of linked data.
 Once we have a linked-data based linguistic resource, we are particularly interested in linking it to other available language resources. In this line of work, we aim to explore cross-lingual and multilingual issues so that best practises and technological solutions will be identified to reduce interoperability issues caused by the different natural languages present in the resources. To this end, together with other working groups in the Action, we are analysing the challenges of cross-lingual interlinking, with a particular focus on cross-lingual link discovery between data, their representation, storage and reuse. With such links established across linked data resources, we are also interested in studying the cross-lingual access and retrieval of the data. In this respect, our work provides a clearer description of cross-linguality, in comparison to multilinguality, and also sheds light on the previous approaches to cross-linguality.
Once we have a linked-data based linguistic resource, we are particularly interested in linking it to other available language resources. In this line of work, we aim to explore cross-lingual and multilingual issues so that best practises and technological solutions will be identified to reduce interoperability issues caused by the different natural languages present in the resources. To this end, together with other working groups in the Action, we are analysing the challenges of cross-lingual interlinking, with a particular focus on cross-lingual link discovery between data, their representation, storage and reuse. With such links established across linked data resources, we are also interested in studying the cross-lingual access and retrieval of the data. In this respect, our work provides a clearer description of cross-linguality, in comparison to multilinguality, and also sheds light on the previous approaches to cross-linguality.
A key aspect along the whole process is the quality of the resources represented as linked data and those linked to. In particular, we are taking a snapshot of the current quality state of the linguistic dataset available in the LOD cloud, and we intend to provide the community with new metrics specifically for linguistic data. For the first aspect, we need to work on data profiling and, as a later step, on data quality assessment. Specifically, in terms of profiling, we are interested in extracting the most frequent patterns and other information present in the linguistic domain. On the other hand, for quality assessment, we are evaluating the different quality metrics.
Aside from the LD datasets as such, the quality dimension is also relevant for LLOD vocabularies. Indeed, the quality of vocabularies has an impact on the quality of datasets that conform to those vocabularies. The quality metrics can be traced both at the level of modelling patterns (which brings us back to the modelling step of the whole process) or metadata/documentation (which puts this stage in relation to that of language resource creation and publication). As any linked data vocabulary, the LLOD ones should satisfy the requirements of the LOV catalogue (https://lov.linkeddata.es/) and should be preferably indexed there. This moves us to detect potential missing pieces of information in these vocabularies and take steps towards meeting such requirements.
In sum, in WG1 our current main lines of work and community building include:
- The analysis of modelling needs of language resources and the development of best practices in collaboration with standardization initiatives,
- the analysis of the current landscape of linked data resources published on the LLOD cloud to gather insights into the tendencies in language resource publication and gaps in language and domain coverage,
- the definition and promotion of policies to help bridge the wide gap in technological support and available data between resourced and under-resourced languages,
- the analysis of challenges of cross-lingual interlinking, with a particular focus on cross-lingual link discovery between data, their representation, storage and reuse, and the elaboration of roadmaps to face them, and
- the definition of new metrics to assess specifically linguistic data quality and the detection and inclusion of missing pieces of information in linguistic vocabularies to promote their sharing and reuse.
In order to provide a first glimpse into these topics to a wider audience, the 1st training school organized by the NexusLinguarum COST Action, held on February 8-12 2021 under the umbrella of the EUROLAN Summer Schools, offered students, academics and practitioners an introduction to Semantic Web, RDF and ontologies, as well as to modelling and querying linguistic data with state-of-the-art ontology models and tools. In addition, the continuous call for Short -Term Scientific Missions (STSMs) offer scholars the opportunity to conduct a research stay related to our current lines of work in the context of WG1.