
»Offence or no offence?«
Use Case in Incivility in Media and Social Media (4.1.1)
The Working Group 4 Use Case in Incivility in Media and Social Media (UC4.1.1) is involved in researching offensive language, exploring its recognition and identification methods in various everyday texts which might contain abusive content. Offensive language research may lead to establishing algorithms that spot offensive content and enable automatic protection of users from undesirable messages.
There are massive amounts of language corpora that address different aspects of offensiveness, using category names such as abusive, toxic, hate speech, profane, etc. And yet, it is hard to reach agreement or find clear linguistic explanations for positing such categories. The UC4.1.1 team is thus trying to prepare a clear, multi-level (and multilingual) taxonomy of offensive language, scrutinizing semantic relationships between words on the basis of the linguistic knowledge and the results of research from various corpus tools.

(The annotation workshop on-site participants, September 28, 2021, Skopje.
Existing data review
Figure presents the distribution of offensive language categories across English datasets. We managed to retrieve 25 datasets, while around 60 datasets were identified and more datasets are available for other languages, in different numbers and sizes.
The available datasets are uneven as to quality. We can observe that many such collections address, say, the category hateful (e.g. hateful, hate speech), though noteworthy semantic discrepancies are identified between them. For example, some datasets use the category hateful as a general, superordinate term for any offensive language type, so to identify its different sub-categories the whole landscape needs to be (re-)organized first. A further analytic and annotation problem is that a great majority of the datasets are published without annotation guidelines or a quality report (e.g. inter-rater agreement), etc., which makes the identification task even harder.
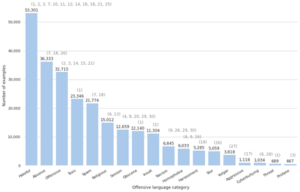
Figure 1: Distribution of different offensive language categories in different datasets.
New data preparation
In the past several months we have been researching the existing corpora of English. We have used exploratory techniques leveraging pure linguistic knowledge (i.e. theory, SketchEngine corpora and tools) and computational linguistic processing of available data (i.e. (non-)contextual embeddings and BERT). As an intermediate result, we proposed a taxonomy of offensive language, consisting of:
- 11 offensive language categories: OFFENSIVE was selected as the umbrella term being the most general category, while other labels were organized into a three-level hierarchy, depending on the particular level specificity
- implicit or explicit expressivenes
- group, individual or mixed target type
- internal, external and border target level
- 7 aspects in which an offense can be represented
- an indicator whether the language is figurative or not
Such an explicit methodology makes the taxonomy of offensive language expressions into multiple categories less problematic and more transparent. In the aim of discussing this problem more extensively, we have organized the hybrid Workshop on Offensive Language, which took place in conjunction with the NexusLinguarum Plenary and MC Meeting in Skopje on September 28, 2021. We were able to attract over 30 participants and managed to discuss our new annotation guidelines. The main part of the workshop focused on hands-on live annotation of selected texts – of different lengths and offense gravity – which gave us further insight into various types of explicit and implicit categories of offensiveness.
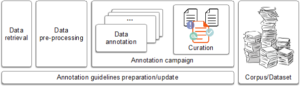
Figure 2: “Standard” approach in creating new annotated corpora.
Findings and next steps
During the workshop we discovered that participant agreement on the textual properties of expressiveness and offence target type and target level annotation was surprisingly high. Some other decisions, such as those regarding the question whether a particular stretch of language is figurative or not, required more linguistic knowledge. Moreover, the basic question of whether a text contains offensive language or not was considered, as observed during the annotation and follow-up discussion, but was not easy to answer in some contexts, and it was also linked with different cultural backgrounds of the annotators.
The outcomes of the Skopje workshop will contribute to further work on the annotation guidelines, and will eventually lead to larger amounts of data collecting, as well as to a new annotation campaign (cf. Figure ).
If you are interested in the topic of offensive language, its identification, ontologies, taxonomy, expliciteness and implicitness, and would like to learn more and to contribute to our discussions and annotation tasks, you are invited to join the UC4.1.1 working meetings.